
지금까지 한 방법은 모든 SkeletalMesh의 모든 vertex를 순회한다는 것이다.
for문만 23309번 도는 것을 확인할 수 있다. 지금 3D Model이 1개만 있어서 성능적으로 그게 문제가 없다고 느껴지지만 이후에 더 늘어나면 더 성능에 부담이 될 것이라고 생각이 된다.
그렇기에 BeginPlay에서 미리 Game Thread가 아닌 다른 Thread에서 vertex만 선별해보기로 했다.
방법은 간단하다.
void AEnemy::SelectVertices(int32 LODIndex)
{
if (!GetMesh() || !ProcMeshComponent){
UE_LOG(LogTemp, Warning, TEXT("CopySkeletalMeshToProcedural: SkeletalMeshComponent or ProcMeshComp is null."));
return;
}
// SkeletalMesh를 가져온다.
USkeletalMesh* SkeletalMesh = GetMesh()->GetSkeletalMeshAsset();
if (!SkeletalMesh){
UE_LOG(LogTemp, Warning, TEXT("CopySkeletalMeshToProcedural: SkeletalMesh is null."));
return;
}
//GetResourceForRendering - Skeletal Mesh의 렌더링 데이터를 가져오는 함수
const FSkeletalMeshRenderData* RenderData = SkeletalMesh->GetResourceForRendering();
if (!RenderData || !RenderData->LODRenderData.IsValidIndex(LODIndex)){
UE_LOG(LogTemp, Warning, TEXT("CopySkeletalMeshToProcedural: LODRenderData[%d] is not valid."), LODIndex);
return;
}
//SkeletalMesh에서 LODRenderData를 가져온다.LODRenderData는 버텍스 데이터, 인덱스 데이터, 섹션 정보 등이 포함
//FSkeletalMeshLODRenderData란 LOD의 Mesh 데이터를 가지고 있는 구조체이다.
const FSkeletalMeshLODRenderData& LODRenderData = RenderData->LODRenderData[LODIndex];
//SkinWeightVertexBuffer를 가져온다. -> vertex가 어떤 Bone에 영향을 받는지 저장하는 데이터이며 Animation에서 사용 예정
const FSkinWeightVertexBuffer& SkinWeights = LODRenderData.SkinWeightVertexBuffer;
//위치를 들고온다.
FTransform MeshTransform = GetMesh()->GetComponentTransform();
FVector TargetBoneLocation = GetMesh()->GetBoneLocation(TargetBoneName);
int32 vertexCounter = 0;
for (const FSkelMeshRenderSection& Section : LODRenderData.RenderSections){
//NumVertices - 해당 Section의 Vertex 수, BaseVertexIndex - 해당 Section의 시작 Vertex Index
const int32 NumSourceVertices = Section.NumVertices;
const int32 BaseVertexIndex = Section.BaseVertexIndex;
for (int32 i = 0; i < NumSourceVertices; i++){
const int32 VertexIndex = i + BaseVertexIndex;
//vertex의 위치를 가져온다. -> LODRenderData.StaticVertexBuffers.PositionVertexBuffer(현재 LOD의 Vertex 위치 데이터를 저장하는 버퍼)
//.VertexPosition(VertexIndex)-> VertexIndex의 위치를 가져온다. 반환 타입이 FVector3f이다.
const FVector3f SkinnedVectorPos = LODRenderData.StaticVertexBuffers.PositionVertexBuffer.VertexPosition(VertexIndex); //로컬 좌표 반환
FVector WorldVertexPosition = MeshTransform.TransformPosition(FVector(SkinnedVectorPos)); // FVector3f -> FVector 변환 & 로컬 -> 월드 좌표
//UE_LOG(LogTemp, Display, TEXT("WorldVertexPosition : %s"), *WorldVertexPosition.ToString());
float DistanceToBone = FVector::Dist(WorldVertexPosition, TargetBoneLocation);
//TargetBoneLocation을 기준으로 일정 거리 내에 있는 Vertex만 추가해서 Procedural Mesh 생성
if (DistanceToBone <= CreateProceduralMeshDistance)
{
// 위치 정보 추가
FVector LocalVertexPosition = FVector(SkinnedVectorPos);
VertexIndexMap.Add(VertexIndex, vertexCounter);
//WorldVertexPosition을 사용하면 다른 위치에 Procedural Mesh가 생성된다.
FilteredVerticesArray.Add(LocalVertexPosition);
vertexCounter += 1;
// 노멀(Normal), 탄젠트(Tangent) 추가
const FVector3f Normal = LODRenderData.StaticVertexBuffers.StaticMeshVertexBuffer.VertexTangentZ(VertexIndex);
const FVector3f TangentX = LODRenderData.StaticVertexBuffers.StaticMeshVertexBuffer.VertexTangentX(VertexIndex);
const FVector2f SourceUVs = LODRenderData.StaticVertexBuffers.StaticMeshVertexBuffer.GetVertexUV(VertexIndex, 0);
Normals.Add(FVector(Normal));
Tangents.Add(FProcMeshTangent(FVector(TangentX), false));
UV.Add(FVector2D(SourceUVs));
//VertexColors.Add(FColor(0, 0, 0, 255));
VertexColors.Add(FColor(0, 0, 0, 255));
}
}
}
//UE_LOG(LogTemp, Display, TEXT("VertexIndexMan Count : %d"), VertexIndexMap.Num());
//LODRenderData.MultiSizeIndexContainer.GetIndexBuffer()는 원래 Skeletal Mesh의 각 vertex가 어떻게 삼각형으로 구성되어있었는지를 들고온다.
const FRawStaticIndexBuffer16or32Interface* IndexBuffer = LODRenderData.MultiSizeIndexContainer.GetIndexBuffer();
if (!IndexBuffer){
UE_LOG(LogTemp, Warning, TEXT("CopySkeletalMeshToProcedural: Index buffer is null."));
return;
}
//현재 LOD의 총 Index 수를 가져온다.
const int32 NumIndices = IndexBuffer->Num();
Indices.SetNum(NumIndices); // 모든 값을 0으로 초기화하며 메모리 공간 확보보
for (int32 i = 0; i < NumIndices; i+=3){
//IndexBuffer Get(i) - 현재 처리 중인 삼각형을 구성하는 버텍스 인덱스를 가져옴.
//VertexIndex : Get(0) = a, Get(1) = b, Get(2) = c로 abc삼각형, Get(3) = c, Get(4) = d, Get(5) = a로 cda삼각형 (여기서 abcd는 FVector위치라고 취급)
//즉, 첫 BaseVertexIndex에서 그려지는 삼각형부터 순서대로 삼각형이 그려지는 vertex의 Index를 가져온다.
//결과적으로 Indices를 순환하면 3개씩 묶어서 삼각형을 그릴 수 있다.
//uint32가 반환되어 int32로 Casting, 데이터 일관성을 위해 Casting한다.
//Indices[i] = static_cast<int32>(IndexBuffer->Get(i));
//아래 코드는 3각형을 이루는 3개의 i를 들고오는 것이다.
int32 OldIndex0 = static_cast<int32>(IndexBuffer->Get(i));
int32 OldIndex1 = static_cast<int32>(IndexBuffer->Get(i + 1));
int32 OldIndex2 = static_cast<int32>(IndexBuffer->Get(i + 2));
int32 NewIndex0 = VertexIndexMap.Contains(OldIndex0) ? VertexIndexMap[OldIndex0] : -1;
int32 NewIndex1 = VertexIndexMap.Contains(OldIndex1) ? VertexIndexMap[OldIndex1] : -1;
int32 NewIndex2 = VertexIndexMap.Contains(OldIndex2) ? VertexIndexMap[OldIndex2] : -1;
// 기존 VertexIndex가 NewVertexIndex에 포함된 경우만 추가 - 실제로 내가 vertex 수집한 곳에 있는 Index인지 확인한다.
//NewIndex >= FilteredVerticesArray.Num() - VertexIndexMap이 잘못된 값을 반환하거나, Indices 배열에 유효하지 않은 인덱스가 추가될 때 발생
if (NewIndex0 < 0 || NewIndex0 >= FilteredVerticesArray.Num() || NewIndex1 < 0 || NewIndex1 >= FilteredVerticesArray.Num() || NewIndex2 < 0 || NewIndex2 >= FilteredVerticesArray.Num()){
//UE_LOG(LogTemp, Warning, TEXT("Skipping triangle due to invalid indices: (%d, %d, %d) → (%d, %d, %d)"), OldIndex0, OldIndex1, OldIndex2, NewIndex0, NewIndex1, NewIndex2);
}
else{
Indices.Add(NewIndex0);
Indices.Add(NewIndex1);
Indices.Add(NewIndex2);
}
}
//
// for (int32 i = 0; i < FilteredVerticesArray.Num(); i++) {
// // 잘린 부분의 버텍스를 Black(0, 0, 0)으로 설정
// VertexColors.Add(FColor(0, 0, 0, 0)); // 알파 값 포함
// }
}이렇게 Vertex를 모으는 함수를 따로 지정해준다.
그리로 BeginPlay에서 다음과 같이 작성해준다.
AsyncTask(ENamedThreads::AnyBackgroundThreadNormalTask, [this]()
{
this->SelectVertices(0);
});이렇게 하면 다른 Thread에서 vertex를 선별하기 때문에 성능적으로 나아진다.
그리고 Skeletal Mesh 위치에 Procedural Mesh를 생성하는 코드는 따로 뺀다.
void AEnemy::CopySkeletalMeshToProcedural(int32 LODIndex)
{
if (!GetMesh() || !ProcMeshComponent){
UE_LOG(LogTemp, Warning, TEXT("CopySkeletalMeshToProcedural: SkeletalMeshComponent or ProcMeshComp is null."));
return;
}
//Skeletal Mesh의 Location과 Rotation을 들고온다.
FVector MeshLocation = GetMesh()->GetComponentLocation();
FRotator MeshRotation = GetMesh()->GetComponentRotation();
//Skeletal Mesh의 Location과 Rotation을 Procedural Mesh에 적용한다.
ProcMeshComponent->SetWorldLocation(MeshLocation);
ProcMeshComponent->SetWorldRotation(MeshRotation);
//Section Index - 어떤 Section부터 시작하는가?, Vertices - 어떤 vertex를 사용하는가?
//Indices - 어떤 삼각형 구조를 사용하는가?, Normals, UV, Colors, Tangents, bCreateCollision - 충돌 활성화
ProcMeshComponent->CreateMeshSection(0, FilteredVerticesArray, Indices, Normals, UV, VertexColors, Tangents, true);
//위에선 LOD Section별로 Vertex를 가져와서 모두 처리했지만 여기서는 GetMaterial(0)로 0번째만 Material을 가져와서 적용함. 즉, 0번째 Material만 적용됨.
//더 적용하기 위해선 수정 필요.
UMaterialInterface* SkeletalMeshMaterial = GetMesh()->GetMaterial(0);
if (SkeletalMeshMaterial){
ProcMeshComponent->SetMaterial(0, SkeletalMeshMaterial);
//UE_LOG(LogTemp, Display, TEXT("Applied material from SkeletalMesh to ProceduralMesh."));
} else UE_LOG(LogTemp, Warning, TEXT("SkeletalMesh has no material assigned."));
}
결과 확인
수치로 한번 살펴보자 마네킹을 100개로 늘린 상태이다.
그냥 GameThread에서 BeginPlay에 했을 경우다.
왼쪽 아래에 있는 그래프에서 초록색이 Fream이고 붉은색이 GameThread 그래프이다.
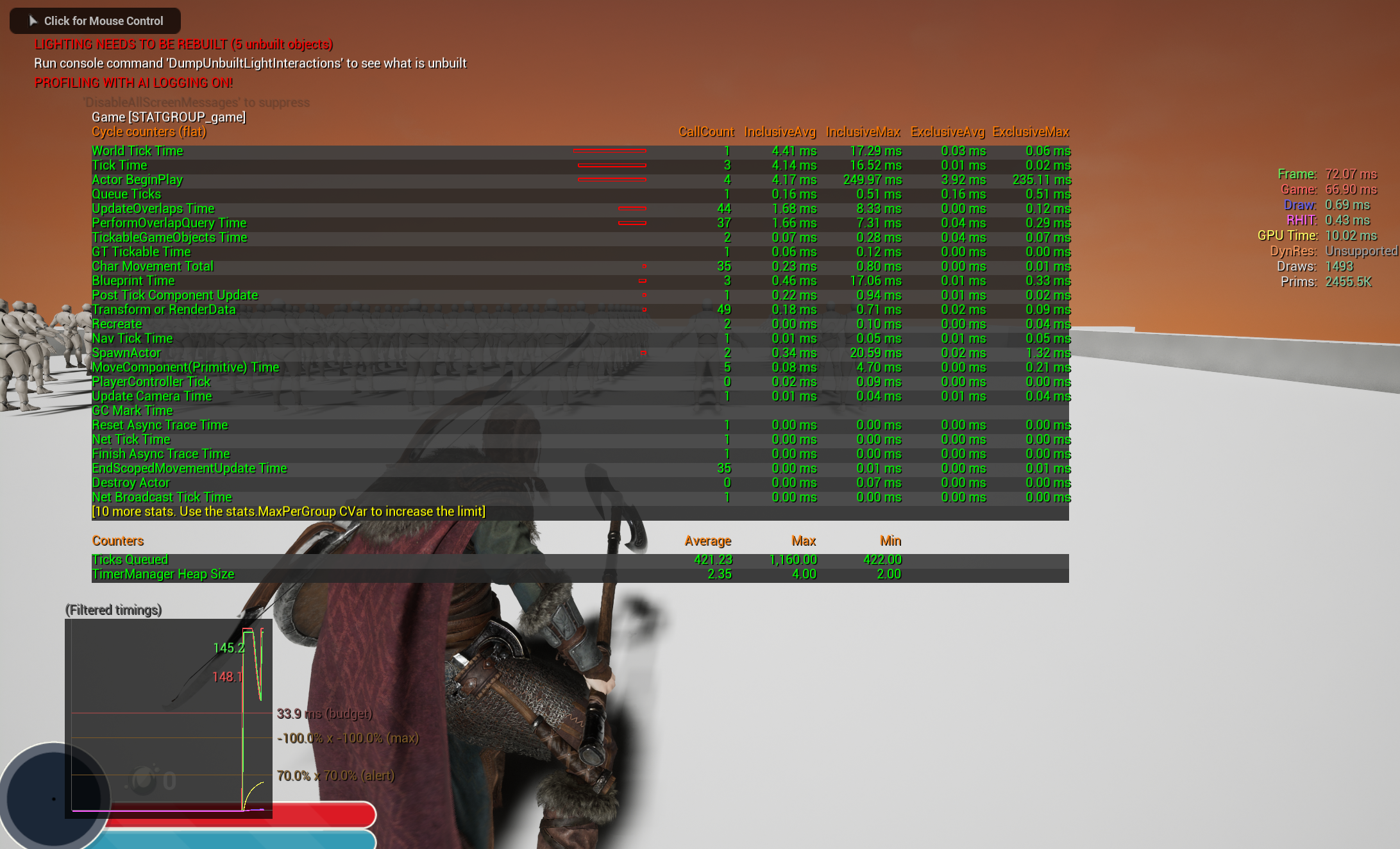
이 결과는 첫 포스트로 적은 글 (Skeletal Mesh 모든 vertex 수집)의 결과이다.

이 결과는 vertex를 선별해서 수집하는 결과이다. 의외로 이게 더 성능적으로 더 걸린다.
Dist 계산과 Index Buffer를 재구성해야 해서 성능적으로 더 먹는다고 판단된다.
절단을 사용하기 위해서 vertex를 선별해서 수집할 것이기 때문에 vertex 수집을 다른 스레드로 보냈을 때의 결과이다.

수치상으로 보나 그래프의 최정점 길이를 보나 현재 상태가 더 성능이 낫다는 것을 확인할 수 있다.
추가적으로 궁금해서 해본 실험이다.
둘다 Game Thread에서 실행하였다.

모든 Vertex로 Procedural Mesh를 만들었을 때의 결과이다.

이건 vertex를 선별해서 만들었을 때의 경우이다.
Procedrual Mesh를 만드는 것 까지 했을 때는 vertex를 선별해서 만들었을 때 성능이 더 낫다는 것을 확인 가능하다.